AI時代來臨,我們不能不問:「這樣對嗎?」
近年AI技術突飛猛進,特別是在圖像生成領域,幾乎已能以假亂真。Facebook近期出現的「Illustrious」AI動漫模型廣告,正是一例。他們大肆宣傳能創造出「完美無瑕」的動漫角色,強調擺脫千篇一律的AI風格。但背後真正令人震驚的是:這些所謂的「美學升級」,竟是建立在大量繪師作品之上——包括許多明確表示拒絕AI使用其創作的藝術家。當AI技術愈趨成熟,我們更不能忽略「資料從哪裡來」這個問題。
公開資料 ≠ 合法使用?挖掘訓練庫後的發現
出於好奇與技術背景,我實際去查閱Illustrious於HuggingFace上所公布的訓練資料來源。結果出乎預料——他們所使用的資料庫,竟包含由nyanko7用戶上傳、超過68萬筆圖像資料,以及數十萬位畫師的作品紀錄。在名為「artist_urls」與「artist」的檔案中,清楚列出了無數知名藝術家,其中包括台灣繪師貓鯨、張熊與空罐王等人。而這些人中,有些甚至早已在自己的社群平台上明文寫下「Do not use my work for AI」。這樣的做法真的妥當嗎?甚至所有繪師被打上了「編號」如同牛羊一般。
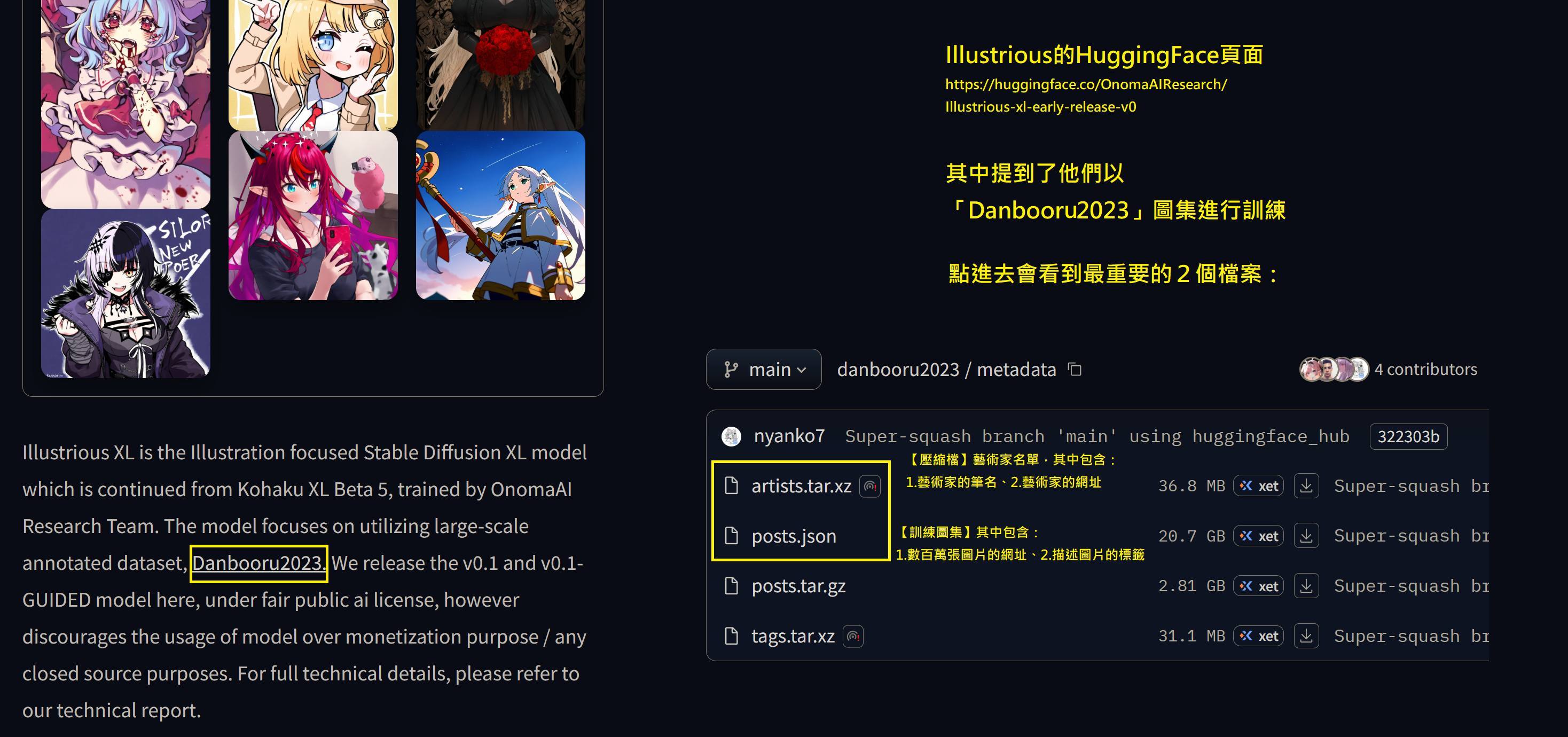
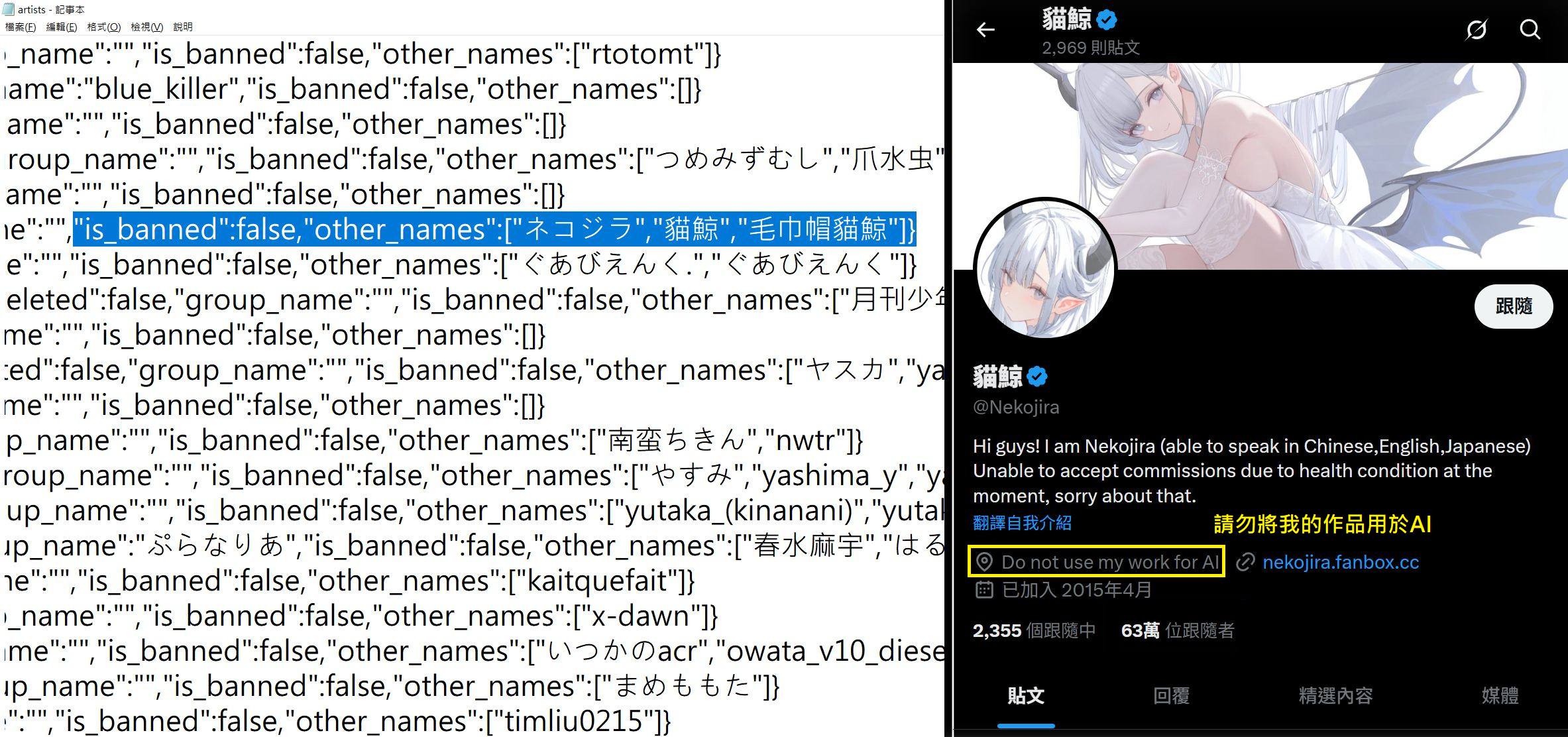
繪師不是「素材來源」,他們有名字也有意志
翻查資料庫的json檔後,可以明確地看到每張作品的來源、標籤與分類。空罐王老師辛苦繪製的插圖,卻被冷冰冰地拆解為「1girl」「blonde_hair」「cleavage」「cup」等AI識別標籤。這不只是對作品的物化,更是對創作者的無視。藝術創作是一種深層的個人表達,不是可以任意切割、抽取特徵的「訓練數據」。AI公司若無視創作者的心血與立場,等同將他們視為可消耗的資源,一次次地被榨乾利用。
方向選擇的十字路口:有些AI正嘗試走上負責任的道路
幸運的是,AI界並非全然黑暗。一些團隊與平台已開始嘗試更道德的訓練方式。像是:
Krea AI:明確標示來源與授權狀態,並設計「opt-out」機制,讓藝術家可以選擇不被納入資料集。
Adobe Firefly:僅使用Adobe Stock內授權可商用的素材訓練模型,並與創作者分享收益。
Scenario.gg:提供遊戲開發用圖像生成工具,且允許使用者用自己的授權素材訓練模型,完全避開未經同意的數據。
這些做法證明:「尊重創作者」與「技術進步」並非衝突對立,而是可以並行的價值選擇。
讓AI成為創作者的幫手,而非對手
AI應該成為創作者的輔助工具,而非剽竊者。若AI工具能提供更透明的訓練資料管理、明確的來源標示與創作者授權機制,將不只降低爭議,更能真正贏得創作社群的信任。此外,推動立法讓平台公開訓練集來源、建立「AI透明標章」,或許也是我們可以共同努力的方向。
如果AI產業願意聆聽創作者聲音、建立尊重與合作的框架,那麼未來的AI創作,不必建立在剝削與爭議之上,而可以成為人類創意的新延伸。